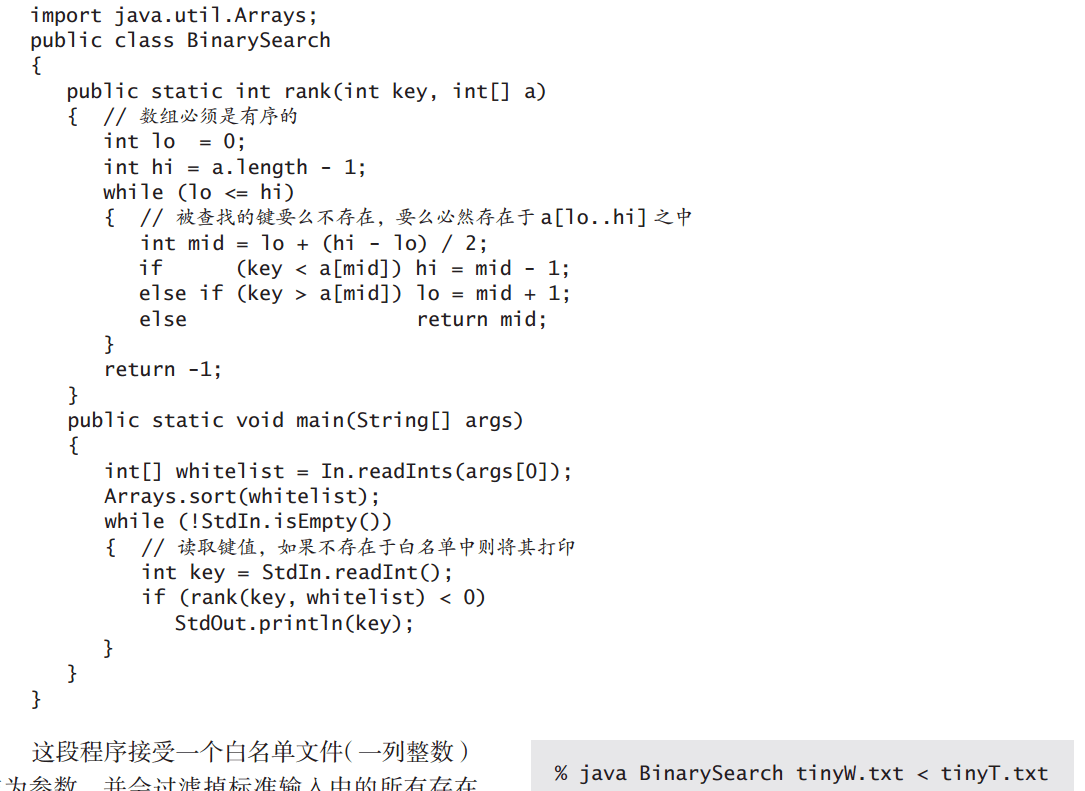
BinarySearch作为算法4这本书的第一个程序,相信很多人都有疑问,在命令行中,课本给出的
java BinarySearch largeW.txt < largeT.txt
关于重定向,本站的Java重定向和管道以及课本的第24页都有简介,但是上面这段话到底是什么意思呢?
首先,我们创建largeW.txt 和 largeT.txt 这两个文本文件,内容编辑如下:
largeW.txt: 1 2 3 4 5 6 7 8 largeT.txt 1 2 3 4 5 6 7 8 9
接下来我们在命令行中执行java BinarySearch largeW.txt < largeT.txt,如下图:
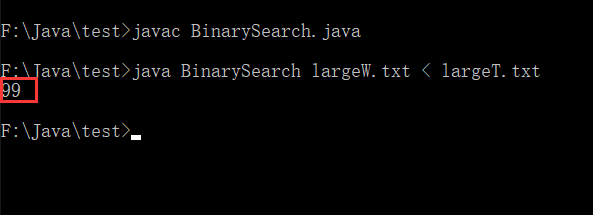
可以看到,输出的99,也就是说,上述代码是将largeT.txt中的所有数字作为key,largeW.txt 中的所有数字作为查询的数组,也就是将largeT.txt中的每个数字作为key在largeW.txt中查找。
读懂了上述代码,那么largeW.txt < largeT.txt到底是什么意思呢?其实这大家有疑问,主要的原因是因为将largeW.txt < largeT.txt看成另一个整体这里largeW.txt < largeT.txt 其实是两部分 :
largeW.txt 作为args[0]
< largeT.txt 作为重定向输入
上述代码首先采用args[0] 将largeW.txt文件的内容,保存在了whitelist数组中 而接下来的 < largeT.txt 采用了重定向标准输入,也就是说,此时系统直接读取了largeT.txt作为了输入流,所以直接可以读取这个文件保存在key变量里了。
为了证明上面的理论,我们将< largeT.txt 去掉,如下图:
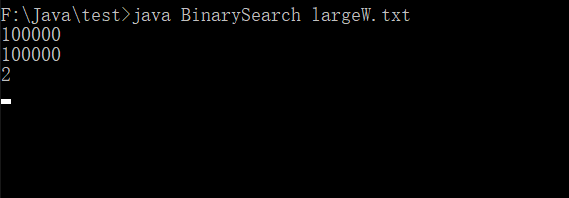
可以看到,此时需要我们手动输入了,输入10000,没有找到这个数字,所以输出,而输入2,找到了则不输出。


请登录之后再进行评论